Servers and datasets
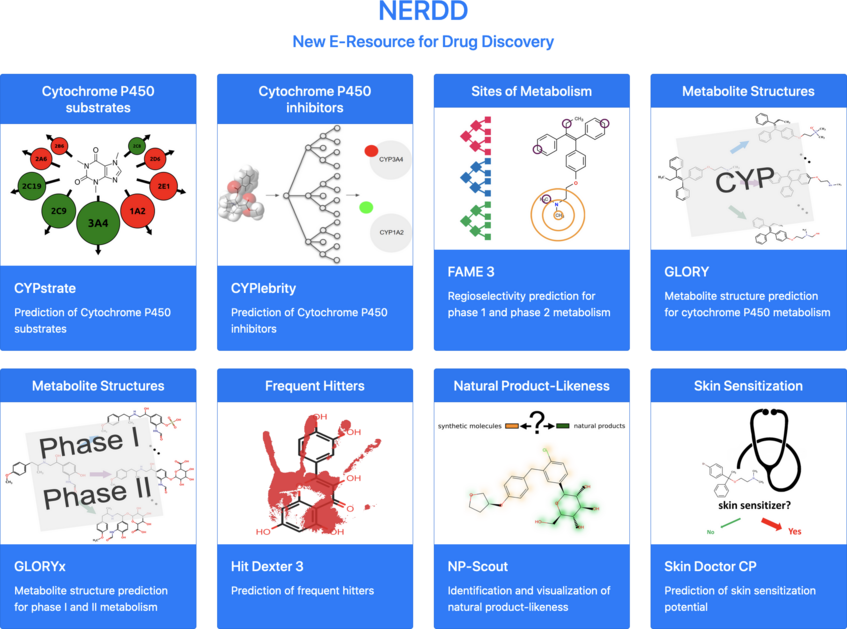
The New E-Resource For Drug Discovery (NERDD)
Many of the tools developed in our research group and described in the "Method development" section of our website are available via NERDD, a maintainable and scalable web platform that meets modern security standards and supports encrypted communication via HTTPS.
The web service is linked to an high-performance computing facility that can handle large numbers of concurrent requests. For additional information, see the Application Note on NERDD published in Bioinformatics.
NERDD features the following in silico models:
Publications
- Stork, C.; Embruch, G.; Šícho, M.; Kops, C. d. B.; Chen, Y.; Svozil, D.; Kirchmair, J.; Ponty, Y., NERDD: A web portal providing access to in silico tools for drug discovery. Bioinformatics 2019, 36, 1291-1292.
BonMOLière
BonMOLière is a collection of small-sized libraries of readily purchasable compounds that have maximized changes of producing genuine hits for a wide range of proteins. The individual libraries were compiled with a novel computational approach that optimizes drug-likeness, likelihood of bioactivity, target space coverage and target novelty.
We found that, in comparison to the random selection of compounds for a library, our new in silico approach generates substantially improved compound sets. Quantified as the “fitness” of compound libraries, the calculated improvements ranged from +60% (for a library of 15,000 compounds) to +184% (for a library of 1000 compounds).
The bundle of data sets can be download here.
Publications
- Mathai, N.; Stork, C.; Kirchmair, J., BonMOLière: Small-sized libraries of readily purchasable compounds, optimized to produce genuine hits in biological screens across the protein space. International Journal of Molecular Sciences 2021, 22, 7773.
The Sperrylite Dataset
The Sperrylite Dataset is a complete collection of high-quality structures of protein-bound ligand conformations extracted from the PDB. It consists of a total of 10,936 high-quality structures of 4548 unique ligands and hence offers a unique resource for the study of protein-bound ligand conformations.
The Sperrylite Dataset was compiled with a recently published cheminformatics pipeline that automatically (i) prepares the chemical structures of small molecules by taking into account the protein environment (in order to determine, e.g., the most likely tautomeric and protonation states); (ii) removes undesirable molecules such as crystallization aids as well as structures with topological and/or geometrical errors; and (iii) rejects structures of low quality. Importantly, the procedure not only includes checks for resolution and DPI, but also employs the recently developed EDIA method to assess the support of individual atoms of a structure by the electron density.
The Sperrylite Dataset contains (among others) a total of 91 ligands represented by at least ten high-quality structures of their protein-bound conformations. Recently we published an analysis of the diversity of the conformations of these ligands. Of these 91 molecules, 69 had at least two distinct conformations (defined by an RMSD greater than 1 Å). For a representative subset of 17 approved drugs and cofactors we observed a clear trend for the formation of few clusters of highly similar conformers. Even for proteins that share a very low sequence identity, ligands were regularly found to adopt similar conformations. For cofactors, a clear trend for extended conformations was measured, although in few cases also coiled conformers were observed.
The Sperrylite dataset has been published in Frontiers in Chemistry. The full dataset can be downloaded from here, whereas the subset of 91 ligands represented by at least ten high-quality conformations is available for download here.
Publications
- Friedrich, N.-O.; Simsir, M.; Kirchmair, J. How Diverse Are the Protein-Bound Conformations of Small-Molecule Drugs and Cofactors? Frontiers in Medicinal Chemistry 2018, 6, 68.
The Platinum Dataset
The Platinum Dataset is a complete subset of unique molecules of the Sperrylite Dataset and contains a total of more than 4500 high-quality structures. It was designed as a benchmark dataset for assessing the performance of conformer ensemble generators. The first version of the Platinum Dataset was published in the Journal of Chemical Information and Modeling in early 2017. An updated version of the dataset was published within the scope of a benchmarking study of eight commercial conformer ensemble generators in the same journal more recently.
The following versions of the Platinum Dataset are available for download:
| Platinum Dataset 2016_01 (as published here) | Platinum Dataset 2017_01 | |
| Data extracted from the PDB on | February 12, 2016 | February 16, 2017 |
| No. of compounds Platinum Dataset | 4626 | 4548 |
| No. of compounds Platinum Diverse Dataset | 2912 | 2859 |
| Compounds present in both the 2016_01 and 2017_01 versions of the Platinum Dataset | 4456 | |
| Compounds present in both the 2016_01 and 2017_01 versions of the Platinum Diverse Dataset | 2763 | |
| Compounds removed from the 2016_01 Platinum Dataset | 170 | |
| Compounds added to the 2017_01 Platinum Dataset | 92 | |
| Download | Platinum Dataset 2016_01 | Platinum Dataset 2017_01 |
| Platinum Diverse Dataset 2016_01 | Platinum Diverse Dataset 2017_01 | |
Change log
Platinum Dataset 2017_01
- This is a revision of the 2017_01 dataset. It forms the basis of our second article on this topic
- Resulting from the use of a refined version of EDIA
- Pipeline now rejects ligands that are wrongly annotated as “free” ligands in the PDB (while actually being covalently bound)
- Pipeline now also rejects ligands with planarity issues of aromatic systems
Platinum Dataset 2016_01
- This is the initial version of the dataset. It forms the basis of our first article on this topic
Publications
- Friedrich, N.-O.; de Bruyn Kops, C.; Flachsenberg, F.; Sommer, K.; Rarey, M.; Kirchmair, J. Benchmarking Commercial Conformer Ensemble Generators. Journal of Chemical Information and Modeling 2017, 57, 2719-2728.
- Friedrich, N.-O.; Meyder, A.; Sommer, K.; Flachsenberg, F.; de Bruyn Kops, C.; Rarey, M., Kirchmair, J. High-quality dataset of protein-bound ligand conformations and its application to benchmarking conformer ensemble generators. Journal of Chemical Information and Modeling 2017, 57, 529-539.